Monitoriza tus servicios con Gatus
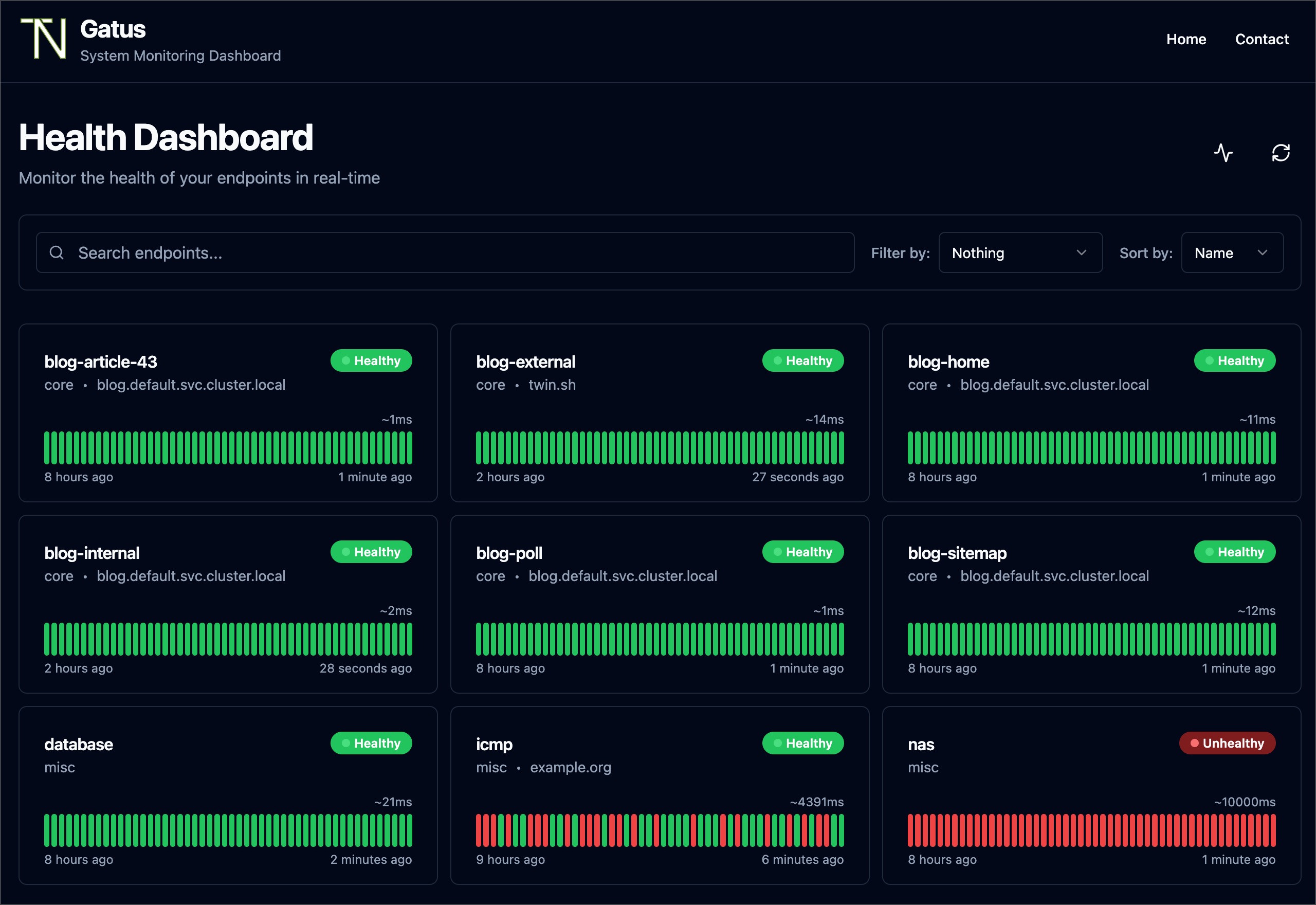
Gatus es un servicio que nos permite disponer de una página de monitorización que nos ayuda a hacer un seguimiento del estado de nuestros servicios. En este artículo explicaré cómo instalarlo y configurarlo en nuestro servidor.
Tabla de contenidos
Introducción
En más de una ocasión me he llevado la desagradable sorpresa de tener uno de mis sitios web caídos durante varias horas sin haberme enterado. Esto puede suponer una buena penalización en el posicionamiento de la web en los buscadores, además de una pérdida de confianza por parte de tus usuarios.
Por ello, estuve buscando una solución de monitorización sencilla de configurar, que se pueda alojar en un servidor propio y que permita enviarnos una notificación cuando se detecte una caída.
Un software muy popular es Uptime Kuma, la cual cumple con las condiciones mencionadas anteriormente. Sin embargo, aunque realizaba bastante bien su cometido, el uso de RAM utilizado me pareció excesivo, superando con consistencia los 200 MB.
Finalmente, encontré una solución que me convenció: Gatus. Ha sido programada en el lenguaje Go, por lo que es bastante liviana (no suele superar los 20 MB de RAM) y dispone de una imagen de Docker para su fácil despliegue.
Desplegando el servicio con Docker
Creamos una carpeta para el servicio y generamos el archivo de compose.yaml con el siguiente contenido.
services:
gatus:
image: twinproduction/gatus:stable
restart: unless-stopped
ports:
- "8080:8080"
volumes:
- ./config:/config
- ./data:/data/Podemos cambiar el puerto asignado al servicio (como siempre, el del host es el de la izquierda) y mapeamos las carpetas de config y data para persistir los datos del contenedor.
Si ya has utilizado anteriormente Docker Compose, sabrás que levantamos el servicio con sudo docker compose up -d.
Configuración del servicio
A diferencia de otras soluciones, Gatus no dispone de una interfaz web para configurar el servicio o añadir nuevos endpoints a monitorizar. Por el lado bueno, esto lo hace más seguro, dado que desde internet sólo exponemos una página de sólo lectura.
Para configurarlo, lo hacemos modificando el archivo config/config.yaml. El servicio detectará automáticamente los cambios realizados en él, por lo que no es necesario hacer ningún reinicio. A continuación indico ejemplos de configuración por secciones.
Almacenamiento
Disponemos de la opción de almacenar los datos en memoria (es decir, se eliminarán al detener el contenedor), en una base de datos SQLite o en una base de datos Postgres.
En mi caso, lo configuro con SQLite en en directorio de data.
storage:
type: sqlite
path: /data/data.db
Notificaciones
Para estar al tanto de una incidencia, podemos recibir una notificación tan pronto se detecte que un endpoint no cumple las condiciones requeridas para considerarse como activo, así como otra notificación cuando vuelve a estar bien.
Gatus ofrece una gran cantidad de integraciones, incluyendo envíos por email, Telegram, Microsoft Teams y Discord, entre otros. En mi caso, lo tengo integrado con ntfy, cuyo ejemplo de configuración podéis ver a continuación.
alerting:
ntfy:
url: "https://ntfy.ejemplo.com"
topic: "tema_ejemplo"
priority: 3
token: "token_ejemplo"
default-alert:
description: "health check fallido"
send-on-resolved: true
failure-threshold: 1
success-threshold: 1
Además de la configuración propia de ntfy de url, topic y token, podemos definir con failure-threshold el número de veces que tiene que fallar un endpoint hasta enviar la notificación. Yo lo tengo puesto a 1 para que avise tan pronto encuentre un error.
Con send-on-resolved: true establecemos que queremos recibir la notificación también cuando el endpoint vuelva a estar disponible. Similar a la configuración anterior, success-threshold define el número de veces que el endpoint debe estar disponible para enviar la notificación.
Endpoints a monitorizar
En esta sección establecemos los endpoints cuyo seguimiento queremos realizar. Pongo un ejemplo del seguimiento para mi página personal y la del blog.
endpoints:
- name: "Adrián JG Web"
group: adrianjg
url: "https://www.adrianjg.es"
interval: 15m
conditions:
- "[STATUS] == 200"
alerts:
- type: ntfy
- name: "Adrián JG Blog"
group: adrianjg
url: "https://blog.adrianjg.es"
interval: 15m
conditions:
- "[STATUS] == 200"
alerts:
- type: ntfyComo se ve en el ejemplo, podemos usar group para agrupar los endpoint relacionados. Con interval establecemos cada cuándo se hará la comprobación (en mi ejemplo, cada 15 minutos).
En conditions podemos establecer una o varias condiciones para que se considere el servicio como válido. Mi ejemplo es bastante simple, dado que sólo comprueba que se devuelva una respuesta HTTP 200, pero podemos añadir condiciones más complejas como tiempos de respuesta, valores del body o tiempo restante para la expiración del certificado.
Por último, le indico con alerts.type que las alertas vayan por ntfy.
Autenticación
Este paso es opcional, dado que podemos dejarlo sin configurar para que la página de estatus sea accesible por todo el mundo.
Si preferimos protegerlo mediante autenticación, tenemos la opción de habilitar una autenticación HTTP básica o integrarlo con un cliente OAuth2.
En mi ejemplo, lo configuro con autenticación básica, indicando el usuario y la contraseña, la cual tiene que estar hasheada con Bcrypt y adicionalmente codificada en Base64.
security:
basic:
username: "usuario_ejemplo"
password-bcrypt-base64: "ejemplo_contraseña_hasheada_base64"
Configurando Caddy como reverse proxy
En este ejemplo utilizaré Caddy, pero se podría utilizar cualquier otra solución de proxy inverso. Para más información sobre Caddy, recomiendo echar un vistazo al artículo. donde explico cómo configurarlo.
Modificamos el archivo Caddyfile para añadir la configuración del sitio como proxy inverso, referenciando la red del host al puerto que configuramos en el archivo de compose de Gatus.
subdominio.ejemplo.es {
reverse_proxy host.docker.internal:8080
}
Un vistazo al panel
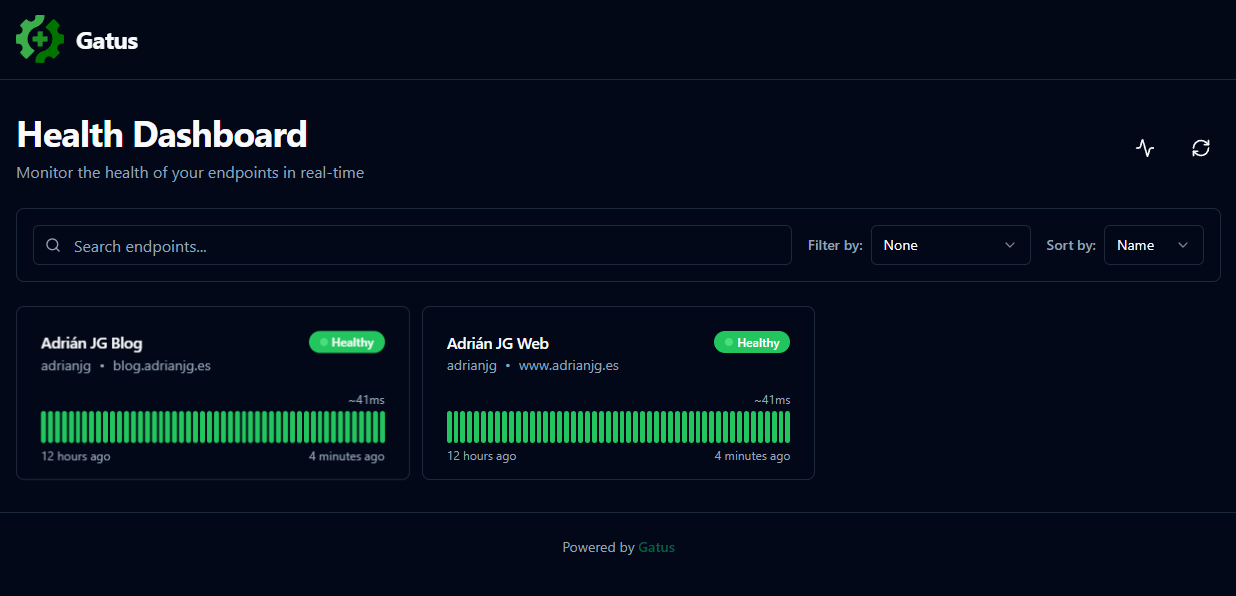
Una vez accedemos a la URL del servicio, se nos presentará la página del panel con un vistazo rápido de los endpoints configurados y sus estatus.
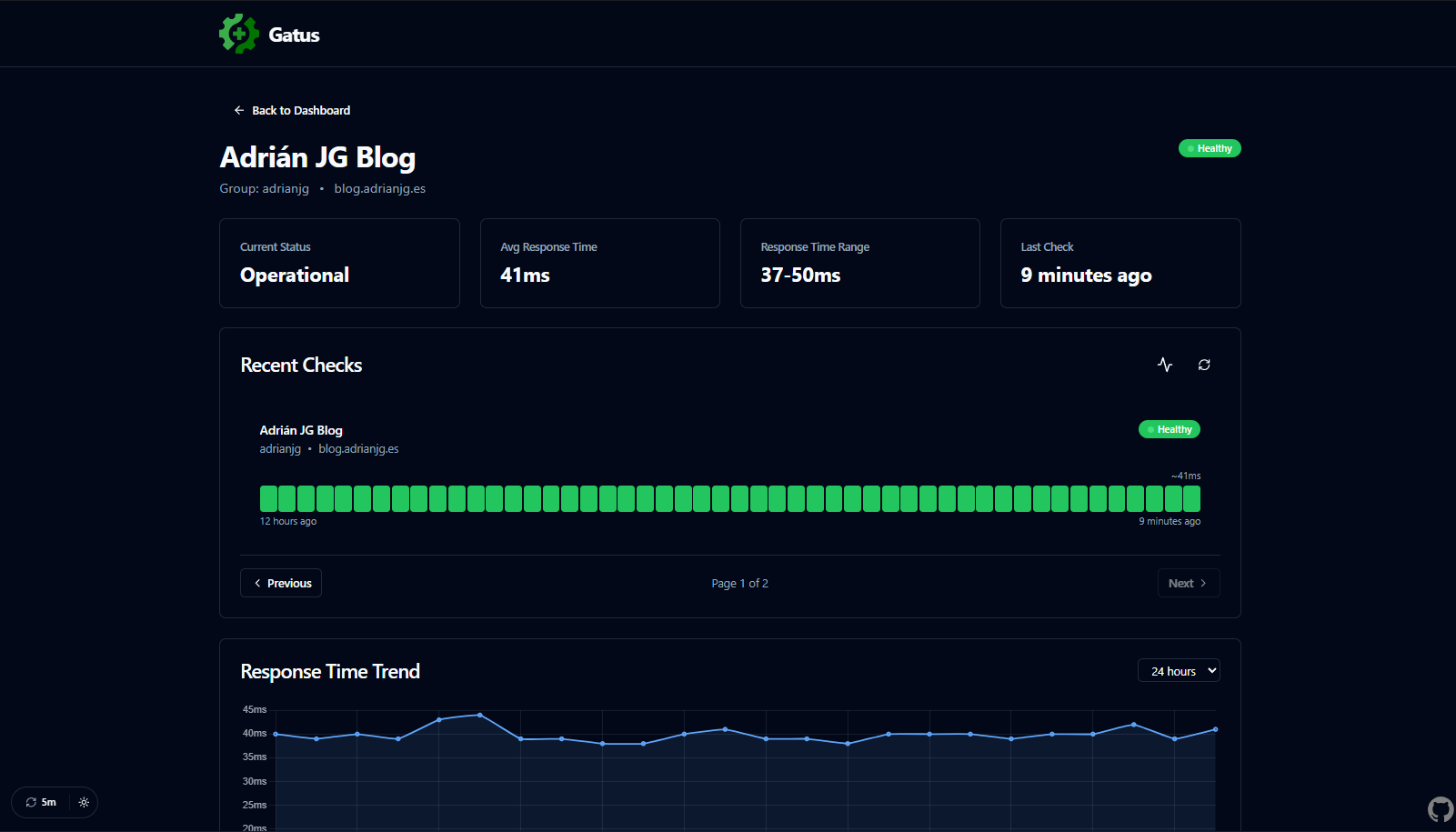
Accediendo a uno de los endpoints veremos información más detallada, incluyendo métricas de tiempo de respuesta, estadísticas de tiempo del servicio en funcionamiento y un histórico de eventos.
Como de costumbre, recomiendo echar un vistazo a la documentación y ejemplos disponibles desde el repositorio en GitHub de Gatus, para poder ir más allá de los ejemplos que indico y poder sacarle el mayor partido posible al servicio.
Espero que te haya sido de utilidad esta lectura. ¡Ahora, a fardar de servicios que casi nunca se caen!